519 billion parameters. The number alone may be hard to grasp, but within it lies South Korea’s endeavor towards AI sovereignty. In early 2026, SK Telecom passed the first phase evaluation of the nation’s flagship Sovereign AI Foundation Model Project* and advanced to Phase 2.
* Sovereign AI Foundation Model Project: A national AI infrastructure initiative led by the Ministry of Science and ICT to develop a globally competitive, domestically built AI foundation model
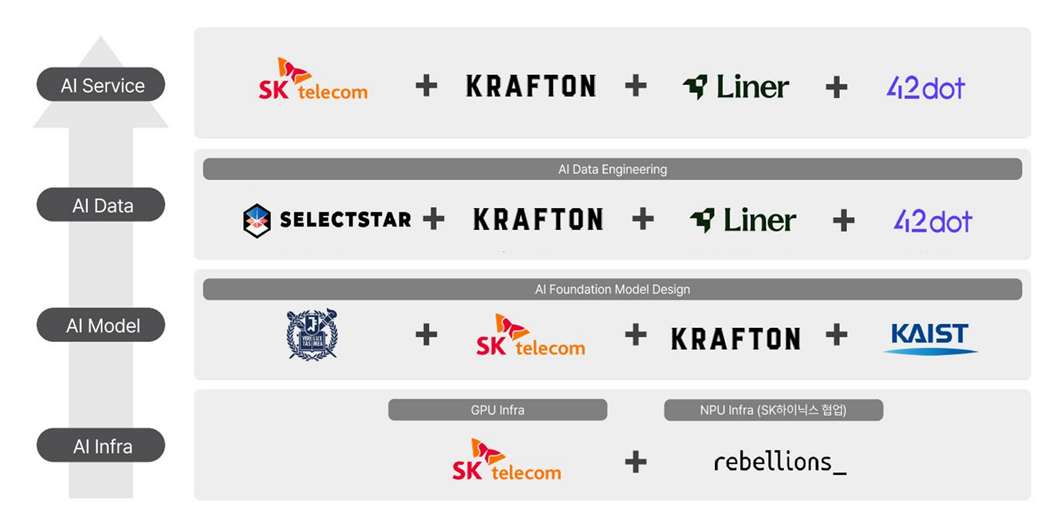
SKT Consortium Participants
* SKT Consortium: A consortium comprising eight organizations including Krafton, 42dot, Rebellions, Liner, SelectStar, Seoul National University, and KAIST that developed the “A.X K1” model. The consortium tied for first place on the NIA benchmark in Phase 1 and advanced to Phase 2.
At the center of this effort are Lee Yu-jin, Cheon Sung-jun, and Yang Hyun-ho of SKT’s Omnimodal Foundation Model (OFM) Team, who shared what it means to build a “national flagship AI” and the journey behind it.

(From left) Lee Yu-jin, Yang Hyun-ho, Cheon Sung-jun of the Omnimodal Foundation Model Team
Massive Scale, a Bold Vision for AI as “Social Infrastructure”
Q. What led you to develop a 519-billion-parameter large-scale model in-house? It must have required a significant investment.
A. Cheon Sung-jun: We wanted this large-scale model to be more than a short-term revenue driver. We saw it as a form of social overhead capital (SOC) that contributes to Korea’s entire AI ecosystem. Just as building roads enables countless vehicles to be mobile and create new value, we wanted our AI model to become a solid foundation on which companies and developers can innovate. It was a very important decision in SKT’s transition toward becoming an AI company.
“The larger the model, the better it can learn rare and complex knowledge, and the less it suffers from hallucinations. This hyperscale model is meaningful in and of itself, but it will also serve as ‘social overhead capital (SOC)’ that enables us to efficiently develop smaller specialized models in the future.” — Cheon Sung-jun
Q. Recently, there’s a trend toward smaller but more efficient models. Why did you choose such a large scale of 519 billion parameters?
A. Yang Hyun-ho: We based our decision on the scaling law*. Within the limits of a set budget, time, and computing resources comparable to our competitors, we calculated the most efficient configuration and concluded that a structure with 519B total parameters and 33B active parameters was optimal. We also believed that a strong general-purpose model would deliver superior performance when later specialized for specific domains. Building the most broadly capable model – that is our differentiator.
* Scaling Law: An empirical principle that AI model performance improves predictably based on the relationship between the number of parameters in a model, training data, and computing resources.
MoE and Think Fusion: Achieving Both Efficiency and Performance
Q. Could you explain the MoE (Mixture of Experts) architecture and Think-Fusion technology?
A. Yang Hyun-ho: MoE is a “mixture of experts” model that does not use the entire large-scale model at once. Instead, it selectively activates the expert networks most relevant to a given query. This allows us to maximize cost efficiency by maintaining computational costs comparable to that of a 33-billion-parameter model despite having 519 billion parameters overall. Although the engineering is complex, we are able to obtain high efficiency by only using the active parameters while retaining knowledge at the 519B scale.
A. Cheon Sung-jun: Think Fusion is not an architecture but rather a model that can be toggled to provide answers with or without a Thinking trace – that is, the reasoning process – depending on the option selected. MoE models are most efficient when they handle multiple requests simultaneously. We made it so that we can run a single model and choose the functionality per request instead of running two separate models. Otherwise, maintaining both a “thinking model” and a “general model” would require running two large-scale models or constantly switching models, which would be inefficient.

(From left) Yang Hyun-ho, Cheon Sung-jun of the Omnimodal Foundation Model Team
A Commitment to Optimizing Korean Language Modeling
Q. What differentiates this model in terms of its Korean-language capabilities?
A. Yang Hyun-ho: We used approximately 30% Korean data, which is a far higher proportion than global models and built a separate processor to select Korean sentences requiring rich context. Training on context-dense sentences improves the model’s ability to understand nuance.
A. Cheon Sung-jun: Our tokenizer* is highly efficient for Korean. The same sentence can be represented with fewer tokens, which gives us advantages in speed and power efficiency compared to global models. Internally, we believe the model shows strong performance in Korean mathematics and coding tasks.
* Tokenizer: A preprocessing tool that splits text into tokens, the smallest units an AI model can process. Depending on efficiency, the same sentence can be expressed with fewer tokens.

Demonstration of A. note and A. phone services
“Our superior Korean language capability was possible because we have been developing LLMs since 2018 and operating services like A. (pronounced “A dot”). This allowed us to accumulate high-quality Korean data and expertise. The key is not just quantity, but quality and experience.” — Lee Yu-jin
Fairness and Safety: Non-Negotiable Principles
Q. What principles did you insist on maintaining throughout the project?
A. Lee Yu-jin: Our principle was to avoid benchmark contamination*. To objectively evaluate the performance of the AI model, it must not be exposed to benchmark data during training. Including benchmark answers would raise scores easily but would undermine true generalization* capability, so we strictly avoided it.
* Benchmark Contamination: When the benchmark data used for evaluation leaks into training data, allowing models to score high through memorization rather than genuine capability.
* Generalization: The ability of a model to perform accurately on new data that was not used in the training process.
A. Cheon Sung-jun: Benchmarks are like college entrance exam questions. Since benchmark datasets are publicly available, they may find their way into training data, whether intentionally or not. That can boost evaluation scores, but it also makes it impossible to measure a model’s true capability. We adhered to the principle of competing fairly without looking at the answer sheet.
We also put significant effort into ensuring safety by minimizing harmful or biased outputs, given the impact AI can have on society. We included safety data in the training so the model refuses dangerous requests, such as instructions for making bombs. We wanted to prove our technical excellence through honest and principled methods, and we take even greater pride in the fact that we held to those principles.

(From left) Cheon Sung-jun, Lee Yu-jin of the Omnimodal Foundation Model Team
A. Yang Hyun-ho: We designed the model with real-world use in mind. Since it will eventually be deployed in services like A. and across SK Group affiliates, we aimed to build an AI that is helpful in everyday life and responds kindly to people, not just one that excels at solving math problems.
The Journey from First to Best
Q. What was the most significant achievement or lesson from this project?
A. Cheon Sung-jun: It felt like a maturation process for Korea’s AI ecosystem. We realized the importance of transparent disclosure to prove technological capability. We saw that the Korean government and elite teams are working to advance the ecosystem, and we also experienced growth through that process.
A. Lee Yu-jin: The biggest achievement was that SK Telecom was recognized not just as a telecommunications operator but as a leading AI company. The title “Top 3 National Flagship AI” says a lot. It was highly motivating for all team members.
“We proved the barrier is not insurmountable. We gained confidence that we can catch up with models from China and the U.S. through sustained effort. In some benchmarks, we even achieved better results than DeepSeek.” — Yang Hyun-ho
Q. Now that the team’s advancement to Phase 2 has been confirmed, what are your plans?
A. Cheon Sung-jun: In Phase 1, our model only supported Korean and English, but in Phase 2 we will support more languages. We believe this will facilitate broader adoption and allow for more diverse evaluations.
A. Lee Yu-jin: We will also strengthen agent capabilities. Multimodality will be introduced sequentially, starting with images and later expanding to voice and video processing in the second half of the year.
A. Yang Hyun-ho: The trial-and-error we experienced during Phase 1 preparation will not be repeated. Our internal technical pipeline has been significantly improved, so this phase should be less hectic.
Korea’s AI journey continues. After successfully completing the first phase evaluation, the OFM Team is now full steam ahead in preparations for the next phase. The next chapter of the OFM Team’s journey is eagerly anticipated, as all eyes are on what kind of game changer the national flagship AI becomes as it enters the global stage.

















