

5,190억 개의 파라미터. 숫자만 들으면 막연하게 느껴지지만, 이 거대한 숫자 속에는 대한민국 AI 주권을 향한 도전이 담겨 있다. 2026년 초, SK텔레콤이 국가대표 독자 파운데이션 모델 프로젝트과학기술정보통신부가 주관하는 국가 AI 인프라 확보 사업으로, 글로벌 영향력을 갖춘 국내 독자 AI 파운데이션 모델 개발을 목표 1차 평가에서 통과하여 2단계에 진출했다.
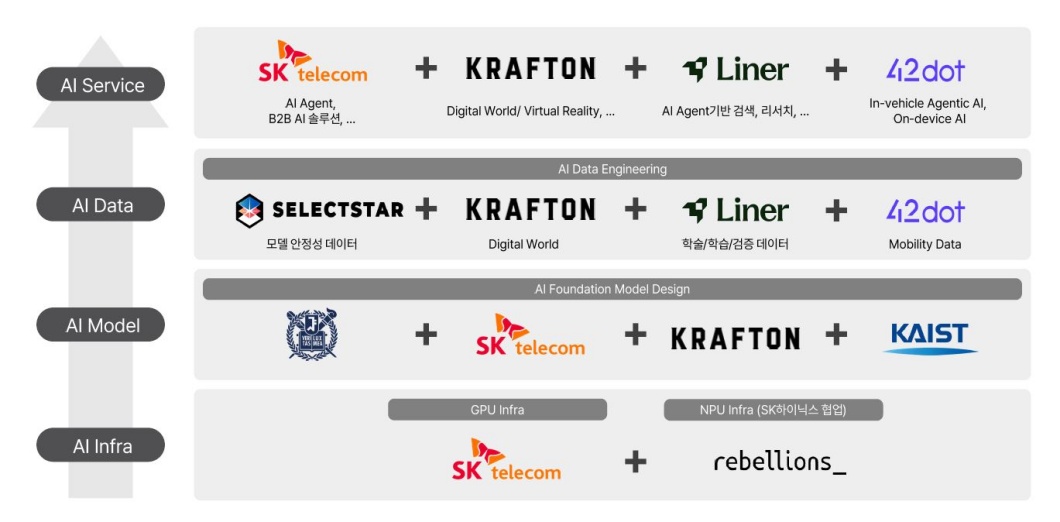
SKT 컨소시엄 참여사
*SKT 컨소시엄은 크래프톤, 포티투닷(42dot), 리벨리온, 라이너, 셀렉트스타, 서울대학교, KAIST 등 8개 기관이 참여해 ‘A.X K1’ 모델을 개발, 1차 평가에서 NIA 벤치마크 공동 1위를 달성하며 2단계에 진출
그 중심에 있던 SKT Omnimodal Foundation Model(이하 OFM)팀의 이유진, 천성준, 양현호 님을 만나 ‘국가대표 AI’를 만든다는 것의 의미와 그 여정에 대해 들어보았다.

(좌측부터) Omnimodal Foundation Model 팀 이유진, 양현호, 천성준 님
압도적 규모, ‘사회 간접 자본’이라는 담대한 비전

Q. 5,190억 파라미터라는 초거대 모델을 자체적으로 개발한 이유가 궁금합니다. 상당한 규모의 투자가 필요한 결정이었을 텐데요.
A. 천성준 : 저희는 이 초거대 모델이 당장의 수익 창출 수단을 넘어, 대한민국 AI 생태계 전반에 기여하는 ‘사회 간접 자본(SOC)’이 되기를 바랐습니다. 도로를 깔면 그 위로 다양한 자동차가 다니며 새로운 가치를 만들 듯, 우리 AI 모델이 여러 기업과 개발자들이 혁신을 펼칠 수 있는 튼튼한 기반이 되길 원했죠. SKT가 AI 컴퍼니로 나아가는 데 있어 매우 중요한 결정이었습니다.
“모델이 클수록 희귀하고 어려운 지식을 더 잘 학습하고, ‘환각 현상(Hallucination)’도 줄어듭니다. 이 거대 모델은 그 자체로도 의미 있지만, 앞으로 더 작은 특화 모델들을 효율적으로 만들어낼 수 있는 ‘사회 간접 자본’이 될 것입니다.” — 천성준 님
Q. 최근에는 모델이 작아도 효율적이면 된다는 흐름도 있는데, 5,190억이라는 대규모를 선택한 이유는 무엇인가요?
A. 양현호 : ‘스케일링 법칙(Scaling Law)’모델 파라미터 수, 학습 데이터 양, 컴퓨팅 자원 간의 관계에 따라 AI 모델 성능이 예측 가능하게 향상된다는 경험 법칙에 기반해 계산했습니다. 한정된 예산, 시간, 그리고 경쟁자들과 비슷한 수준의 컴퓨팅 자원 내에서 가장 효율적인 모델을 계산했을 때, 519B 전체 파라미터에 활성 파라미터 33B를 쓰는 구조가 최적이라는 결론이 나왔습니다. 기본이 잘 된 범용 모델이 나중에 특정 분야에 특화될 때도 더 뛰어난 성능을 발휘할 것이라는 믿음도 있었죠. 가장 범용적인 모델을 만드는 것, 그것이 저희의 차별점입니다.
MoE와 Think Fusion, 효율과 성능을 잡다
Q. MoE(Mixture of Experts·전문가 혼합) 구조와 Think-Fusion 기술에 대해 설명해 주세요.
A. 양현호 : MoE는 ‘전문가 혼합’ 모델로, 거대한 AI 모델 전체를 한 번에 사용하는 것이 아니라, 주어진 질문에 가장 적합한 일부 전문가(Expert) 네트워크만 선택적으로 활성화하는 방식입니다. 이를 통해 5,190억이라는 거대한 파라미터 규모에도 불구하고, 실제 연산량은 330억 파라미터 모델과 비슷하게 유지하여 비용 효율성을 극대화할 수 있는 거죠. 엔지니어링적으로는 까다롭지만, 활성 파라미터만 사용하면서도 519B 규모의 지식을 담을 수 있어 효율성이 매우 좋습니다.
A. 천성준 : Think Fusion은 별도의 구조라기 보다는, 옵션 선택에 따라 ‘Thinking Trace(사고 과정)’가 포함된 답변을 하거나, 사고 과정 없이 답변만 하도록 켜고 끌 수 있는 모델입니다. MoE 모델은 한 번에 여러 요청을 처리해야 효율적인데, 두 가지 모델을 따로 띄울 필요 없이 하나만 띄워놓고 요청에 따라 기능을 선택할 수 있게 만든 겁니다. 만약 ‘생각하는 모델’과 ‘일반 모델’이 따로 있다면 두 개의 거대 모델을 띄워야 하거나, 요청 종류에 따라 모델을 갈아 끼워야 하는 비효율이 발생하죠.

(좌측부터) Omnimodal Foundation Model 팀 양현호, 천성준 님
한국어, 제대로 하고 싶었다
Q. 한국어 특화와 관련해서는 어떤 차별점이 있나요?
A. 양현호 : 글로벌 기업보다 훨씬 높은 비중인 약 30%의 한국어 데이터를 투입했어요. 그리고 한국어 중에서도 맥락이 많이 필요한 문장을 골라내는 별도의 처리기를 만들었습니다. 맥락이 풍부한 문장을 많이 학습해야 문맥을 짚는 능력이 좋아지기 때문입니다.
A. 천성준 : 토크나이저(Tokenizer)텍스트를 AI 모델이 처리할 수 있는 최소 단위(토큰)로 분할하는 전처리 도구. 효율성에 따라 같은 문장도 더 적은 토큰으로 표현 가능하다.의 한국어 효율성이 굉장히 높아요. 같은 문장이라도 더 적은 토큰으로 표현할 수 있어서 속도와 전력 효율 면에서 글로벌 모델 대비 경쟁력이 있습니다. 실제로 한국어 수학과 코딩 분야에서는 내부적으로 높은 성능을 보이고 있다고 판단하고 있어요.

에이닷 노트와 에이닷 전화 서비스 시연 모습
“2018년부터 LLM을 개발하고, 에이닷 등 다양한 서비스를 운영하며 축적해 온 양질의 한국어 데이터와 노하우가 있었기에 가능했습니다. 단순한 데이터의 양이 아닌, 품질과 경험의 차이가 핵심입니다.” — 이유진 님
공정함과 안전성, 타협할 수 없는 원칙성
Q. 프로젝트 준비하는 과정에서 끝까지 지키려고 했던 원칙이 있다면요?
A. 이유진 : ‘벤치마크 오염(Contamination)*’을 시키지 않겠다는 원칙이에요. AI 모델의 성능을 객관적으로 평가하기 위해서는 평가 데이터(벤치마크)가 학습 과정에서 노출되지 않아야 합니다. 벤치마크 문제의 답을 학습 데이터에 넣으면 점수는 쉽게 오르지만, 모델의 진짜 실력인 ‘일반화 능력*’을 위해 절대 넣지 않았습니다.
*벤치마크 오염(Benchmark Contamination): 평가용 벤치마크 데이터가 학습 데이터에 포함되어, 모델이 실제 일반화 능력이 아닌 암기력으로 높은 점수를 받게 되는 문제
*일반화 능력(Generalization): AI 모델이 학습에 사용되지 않은 새로운 데이터에 대해서도 정확한 예측을 수행할 수 있는 능력
A. 천성준 : 벤치마크는 수능 문제 풀이와 비슷합니다. 업계에서는 벤치마크 문제집이 공유되는데, 이걸 학습 데이터에 넣으면 점수는 쉽게 오르지만 모델의 본질을 평가할 수 없게 돼요. 저희는 답지를 보지 않고 공정하게 경쟁하자는 원칙을 끝까지 지켰습니다.
또한, AI가 사회에 미칠 영향을 고려해 유해성, 편향성 등을 최소화하는 ‘안전성’ 확보에도 많은 노력을 기울였습니다. ‘폭탄 제조법’과 같이 사람에게 해를 끼칠 수 있는 질문에는 답변을 거부하도록 안전성 데이터를 학습에 포함시켰습니다. 정직하고 올바른 방법으로 최고의 기술력을 증명하고 싶었고, 이러한 원칙을 지켰기에 더 큰 자부심을 느낍니다.

(좌측부터) Omnimodal Foundation Model 팀 천성준, 이유진 님
A. 양현호 : 저희는 실사용을 염두에 두고 있었어요. 나중에 에이닷 서비스나 그룹사로 확산될 예정이라서, 수학 문제만 잘 푸는 모델이 아니라 사람들에게 친절하게 응답하고 실생활에 도움이 되는 AI를 만들고 싶었습니다.
최초를 넘어 최고를 향한 여정
Q. 이번 프로젝트의 가장 큰 성과나 배움이 있었다면요?
A. 천성준 : 국내 AI 생태계가 성숙해지는 과정이라고 느꼈습니다. 기술력을 증명하기 위해 투명하게 공개하는 것이 중요하다는 걸 깨달았어요. 정부와 정예팀들이 생태계 발전을 위해 노력하고 있음을 느꼈고, 이 과정에서 저희도 성장했습니다.
A. 이유진 : SK텔레콤이 통신사를 넘어 AI 선도 회사 로서 인정을 받은 점이 가장 큰 성과예요. ‘국가대표 AI 3강’이라는 타이틀 하나만으로 많은 것이 설명됩니다. 팀원 모두에게 큰 동기부여가 되었어요.
“넘지 못할 벽이 아니라는 것을 증명했습니다. 중국이나 미국의 모델 성능을 열심히 하면 따라잡을 수 있겠다는 자신감을 얻었어요. 실제로 일부 벤치마크에서는 ‘딥시크(DeepSeek)’보다 좋은 결과가 나오기도 했습니다.” — 양현호 님
Q. 2단계 진출을 확정했는데, 앞으로의 계획은 어떻게 되나요?
A. 천성준 : 1차에서는 한국어와 영어만 지원했지만, 2단계부터는 더욱 다양한 언어를 지원할 예정입니다. 좀 더 ‘확산에 유리한 방향이지 않을까’라는 생각도 갖고 있고, 평가도 다양해질 수 있지 않을까 기대하고 있습니다.
A. 이유진 : 에이전트(Agent) 능력을 강화하는 방향으로도 진행될 거예요. 멀티모달도 순차적으로 적용할 예정입니다. 이미지부터 시작해서 하반기 이후에는 음성, 영상 데이터도 처리할 수 있도록 고도화할 계획이에요.
A. 양현호 : 1차 단계평가를 준비하는 과정에서 겪었던 시행착오들은 다시 발을 헛디디지 않을 겁니다. 내부적인 기술 파이프라인도 고도화되어서 이번에는 저번처럼 바쁘지 않을 것 같습니다.
대한민국 AI의 도전. OFM팀은 1차 평가를 성공적으로 마친 뒤, 본격적으로 다음 단계를 준비하고 있다. 국가대표 AI가 글로벌 무대에서 어떤 ‘게임 체인저’로 성장해 나갈지, OFM팀의 다음 여정이 기대된다.






![[Inside T] “오래 함께하길 잘했다”는 마음을 만들기까지 – Segment팀](https://news-static.sktelecom.com/wp-content/uploads/2026/06/%EC%98%A4%EB%9E%98-%ED%95%A8%EA%BB%98%ED%95%98%EA%B8%B8-%EC%9E%98%ED%96%88%EB%8B%A4%EB%8A%94-%EB%A7%88%EC%9D%8C%EC%9D%84-%EB%A7%8C%EB%93%A4%EA%B8%B0%EA%B9%8C%EC%A7%80-%E2%80%93-Segment%ED%8C%80_PC_ed03-586x379.gif)
![[Inside T] “오래 함께하길 잘했다”는 마음을 만들기까지 – Segment팀](https://news-static.sktelecom.com/wp-content/uploads/2026/06/%EC%98%A4%EB%9E%98-%ED%95%A8%EA%BB%98%ED%95%98%EA%B8%B8-%EC%9E%98%ED%96%88%EB%8B%A4%EB%8A%94-%EB%A7%88%EC%9D%8C%EC%9D%84-%EB%A7%8C%EB%93%A4%EA%B8%B0%EA%B9%8C%EC%A7%80-%E2%80%93-Segment%ED%8C%80_MO_ed03.gif)









